Multi Agent Frameworks
We are strong advocates for the future of AI agents, envisioning a world where autonomous agents communicate and collaborate as a cohesive team to undertake and complete complex tasks. We hold the belief that research is a pivotal element in successfully tackling these complex tasks, ensuring superior outcomes. Consider the scenario of developing a coding agent responsible for coding tasks using the latest API documentation and best practices. It would be wise to integrate an agent specializing in research to curate the most recent and relevant documentation, before crafting a technical design that would subsequently be handed off to the coding assistant tasked with generating the code. This approach is applicable across various sectors, including finance, business analysis, healthcare, marketing, and legal, among others. One multi-agent framework that we’re excited about is LangGraph, built by the team at Langchain. LangGraph is a Python library for building stateful, multi-actor applications with LLMs. It extends the LangChain Expression Language with the ability to coordinate multiple chains (or actors) across multiple steps of computation. What’s great about LangGraph is that it follows a DAG architecture, enabling each specialized agent to communicate with one another, and subsequently trigger actions among other agents within the graph. We’ve added an example for leveraging GPT Researcher with LangGraph which can be found in/multi_agents.
The example demonstrates a generic use case for an editorial agent team that works together to complete a research report on a given task.
The Multi Agent Team
The research team is made up of 7 AI agents:- Chief Editor - Oversees the research process and manages the team. This is the “master” agent that coordinates the other agents using Langgraph.
- Researcher (gpt-researcher) - A specialized autonomous agent that conducts in depth research on a given topic.
- Editor - Responsible for planning the research outline and structure.
- Reviewer - Validates the correctness of the research results given a set of criteria.
- Revisor - Revises the research results based on the feedback from the reviewer.
- Writer - Responsible for compiling and writing the final report.
- Publisher - Responsible for publishing the final report in various formats.
How it works
Generally, the process is based on the following stages:- Planning stage
- Data collection and analysis
- Writing and submission
- Review and revision
- Publication
Architecture
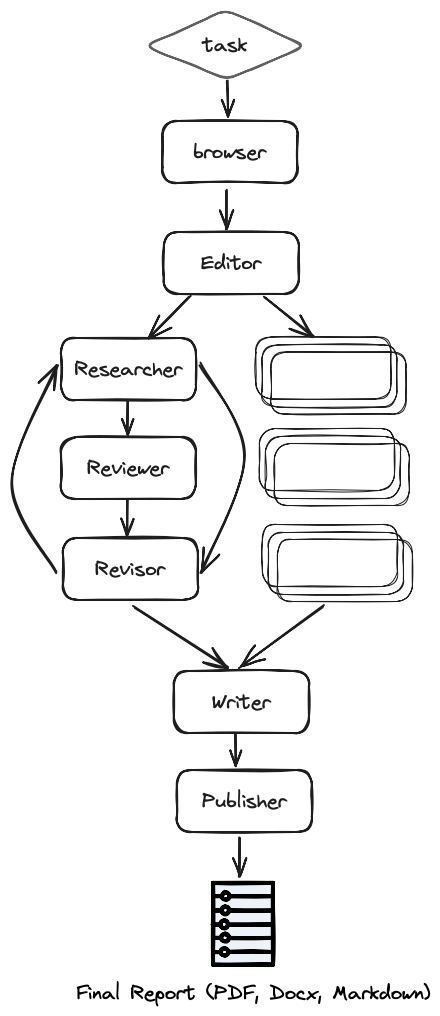
Steps
More specifically (as seen in the architecture diagram) the process is as follows:- Browser (gpt-researcher) - Browses the internet for initial research based on the given research task.
- Editor - Plans the report outline and structure based on the initial research.
- For each outline topic (in parallel):
- Researcher (gpt-researcher) - Runs an in depth research on the subtopics and writes a draft.
- Reviewer - Validates the correctness of the draft given a set of criteria and provides feedback.
- Revisor - Revises the draft until it is satisfactory based on the reviewer feedback.
- Writer - Compiles and writes the final report including an introduction, conclusion and references section from the given research findings.
- Publisher - Publishes the final report to multi formats such as PDF, Docx, Markdown, etc.
How to run
- Install required packages:
- Run the application:
Usage
To change the research query and customize the report, edit thetask.json file in the main directory.
Customization
The config.py enables you to customize GPT Researcher to your specific needs and preferences. Thanks to our amazing community and contributions, GPT Researcher supports multiple LLMs and Retrievers. In addition, GPT Researcher can be tailored to various report formats (such as APA), word count, research iterations depth, etc. GPT Researcher defaults to our recommended suite of integrations: OpenAI for LLM calls and Tavily API for retrieving realtime online information. As seen below, OpenAI still stands as the superior LLM. We assume it will stay this way for some time, and that prices will only continue to decrease, while performance and speed increase over time. It may not come as a surprise that our default search engine is Tavily. We’re aimed at building our search engine to tailor the exact needs of searching and aggregating for the most factual and unbiased information for research tasks. We highly recommend using it with GPT Researcher, and more generally with LLM applications that are built with RAG. Here is an example of the default config.py file found in/gpt_researcher/config/:
llm_provider config param.
You can also change the search engine by modifying the retriever param to others such as duckduckgo, googleAPI, googleSerp, searx and more.
Please note that you might need to sign up and obtain an API key for any of the other supported retrievers and LLM providers.
Agent Example
If you’re interested in using GPT Researcher as a standalone agent, you can easily import it into any existing Python project. Below, is an example of calling the agent to generate a research report:Getting Started
Step 0 - Install Python 3.11 or later. See here for a step-by-step guide. Step 1 - Download the project and navigate to its directory.env file.
For Linux/Temporary Windows Setup, use the export method:
.env file in the current gpt-researcher folder and input the keys as follows:
duckduckgo, googleAPI, googleSerp, searx, or bing. Then add the corresponding env API key as seen in the config.py file.
Quickstart
Step 1 - Install dependenciesUsing Virtual Environment or Poetry
Select either based on your familiarity with each:Virtual Environment
Establishing the Virtual Environment with Activate/Deactivate configuration Create a virtual environment using thevenv package with the environment name <your_name>, for example, env. Execute the following command in the PowerShell/CMD terminal:
env environment, install dependencies using the requirements.txt file with the following command:
Poetry
Establishing the Poetry dependencies and virtual environment with Poetry version~1.7.1
Install project dependencies and simultaneously create a virtual environment for the specified project. By executing this command, Poetry reads the project’s “pyproject.toml” file to determine the required dependencies and their versions, ensuring a consistent and isolated development environment. The virtual environment allows for a clean separation of project-specific dependencies, preventing conflicts with system-wide packages and enabling more straightforward dependency management throughout the project’s lifecycle.
Run the app
Launch the FastAPI application agent on a Virtual Environment or Poetry setup by executing the following command:Try it with Docker
Step 1 - Install Docker Follow the instructions here Step 2 - Create.env file with your OpenAI Key or simply export it
Introduction
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. The agent can produce detailed, factual and unbiased research reports, with customization options for focusing on relevant resources, outlines, and lessons. Inspired by the recent Plan-and-Solve and RAG papers, GPT Researcher addresses issues of speed, determinism and reliability, offering a more stable performance and increased speed through parallelized agent work, as opposed to synchronous operations.Why GPT Researcher?
- To form objective conclusions for manual research tasks can take time, sometimes weeks to find the right resources and information.
- Current LLMs are trained on past and outdated information, with heavy risks of hallucinations, making them almost irrelevant for research tasks.
- Solutions that enable web search (such as ChatGPT + Web Plugin), only consider limited resources and content that in some cases result in superficial conclusions or biased answers.
- Using only a selection of resources can create bias in determining the right conclusions for research questions or tasks.
Architecture
The main idea is to run “planner” and “execution” agents, whereas the planner generates questions to research, and the execution agents seek the most related information based on each generated research question. Finally, the planner filters and aggregates all related information and creates a research report. The agents leverage both gpt3.5-turbo and gpt-4-turbo (128K context) to complete a research task. We optimize for costs using each only when necessary. The average research task takes around 3 minutes to complete, and costs ~$0.1.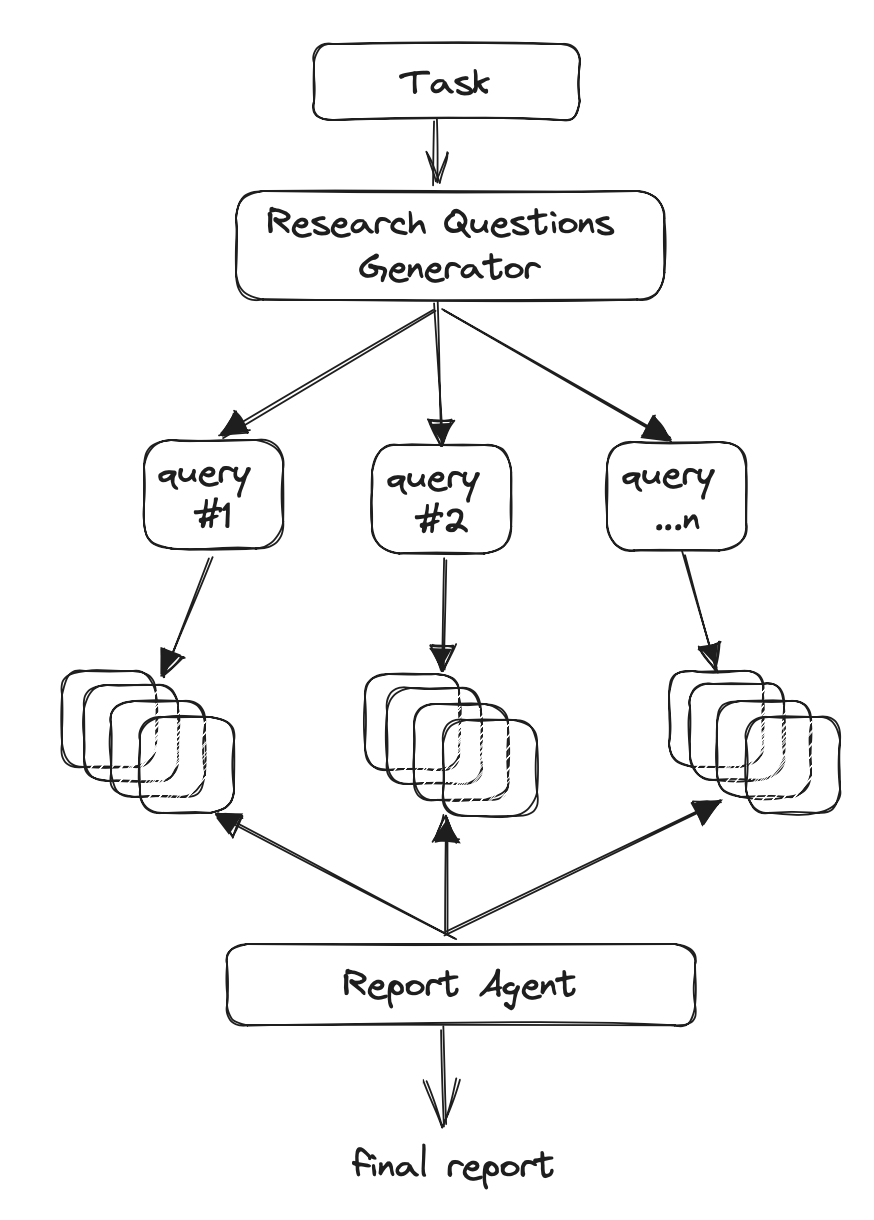
- Create a domain specific agent based on research query or task.
- Generate a set of research questions that together form an objective opinion on any given task.
- For each research question, trigger a crawler agent that scrapes online resources for information relevant to the given task.
- For each scraped resources, summarize based on relevant information and keep track of its sources.
- Finally, filter and aggregate all summarized sources and generate a final research report.
Demo
Tutorials
Features
- 📝 Generate research, outlines, resources and lessons reports
- 📜 Can generate long and detailed research reports (over 2K words)
- 🌐 Aggregates over 20 web sources per research to form objective and factual conclusions
- 🖥️ Includes an easy-to-use web interface (HTML/CSS/JS)
- 🔍 Scrapes web sources with javascript support
- 📂 Keeps track and context of visited and used web sources
- 📄 Export research reports to PDF, Word and more…
Disclaimer
This project, GPT Researcher, is an experimental application and is provided “as-is” without any warranty, express or implied. We are sharing codes for academic purposes under the MIT license. Nothing herein is academic advice, and NOT a recommendation to use in academic or research papers. Our view on unbiased research claims: The whole point of our scraping system is to reduce incorrect fact. How? The more sites we scrape the less chances of incorrect data. We are scraping 20 per research, the chances that they are all wrong is extremely low. We do not aim to eliminate biases; we aim to reduce it as much as possible. We are here as a community to figure out the most effective human/llm interactions. In research, people also tend towards biases as most have already opinions on the topics they research about. This tool scrapes many opinions and will evenly explain diverse views that a biased person would never have read. Please note that the use of the GPT-4 language model can be expensive due to its token usage. By utilizing this project, you acknowledge that you are responsible for monitoring and managing your own token usage and the associated costs. It is highly recommended to check your OpenAI API usage regularly and set up any necessary limits or alerts to prevent unexpected charges.PIP Package
🌟 Exciting News! Now, you can integrate gpt-researcher with your apps seamlessly!Steps to Install GPT Researcher 🛠️
Follow these easy steps to get started:- Pre-requisite: Ensure Python 3.10+ is installed on your machine 💻
- Install gpt-researcher: Grab the official package from PyPi.
- Environment Variables: Create a .env file with your OpenAI API key or simply export it
- Start using GPT Researcher in your own codebase
Example Usage 📝
Specific Examples 🌐
Example 1: Research Report 📚Integration with Web Frameworks 🌍
FastAPI Example:Roadmap
We’re constantly working on additional features and improvements to our products and services. We’re also working on new products and services to help you build better AI applications using GPT Researcher. Our vision is to build the #1 autonomous research agent for AI developers and researchers, and we’re excited to have you join us on this journey! The roadmap is prioritized based on the following goals: Performance, Quality, Modularity and Conversational flexibility. The roadmap is public and can be found here.Tailored Research
The GPT Researcher package allows you to tailor the research to your needs such as researching on specific sources or local documents, and even specify the agent prompt instruction upon which the research is conducted.Research on Specific Sources 📚
You can specify the sources you want the GPT Researcher to research on by providing a list of URLs. The GPT Researcher will then conduct research on the provided sources.Specify Agent Prompt 📝
You can specify the agent prompt instruction upon which the research is conducted. This allows you to guide the research in a specific direction and tailor the report layout. Simplay pass the prompt as thequery argument to the GPTResearcher class and the “custom_report” report_type.
Research on Local Documents 📄
TBD!Troubleshooting
We’re constantly working to provide a more stable version. If you’re running into any issues, please first check out the resolved issues or ask us via our Discord community.Model: gpt-4 does not exist
This relates to not having permission to use gpt-4 yet. Based on OpenAI, it will be widely available for all by end of July.Cannot load library ‘gobject-2.0-0’
The issue relates to the library WeasyPrint (which is used to generate PDFs from the research report). Please follow this guide to resolve it: https://doc.courtbouillon.org/weasyprint/stable/first_steps.html, or you can install this package manually. In case of MacOS you can install this lib usingbrew install glib gobject-introspection
In case of Linux you can install this lib using sudo apt install libglib2.0-dev
Cannot load library ‘pango’
In case of MacOS you can install this lib usingbrew install pango
In case of Linux you can install this lib using sudo apt install libpango-1.0-0
Workaround for Mac M chip users
If the above solutions don’t work, you can try the following:- Install a fresh version of Python 3.11 pointed to brew:
brew install python@3.11 - Install the required libraries:
brew install pango glib gobject-introspection - Install the required GPT Researcher Python packages:
pip3.11 install -r requirements.txt - Run the app with Python 3.11 (using brew):
python3.11 -m uvicorn main:app --reload